|
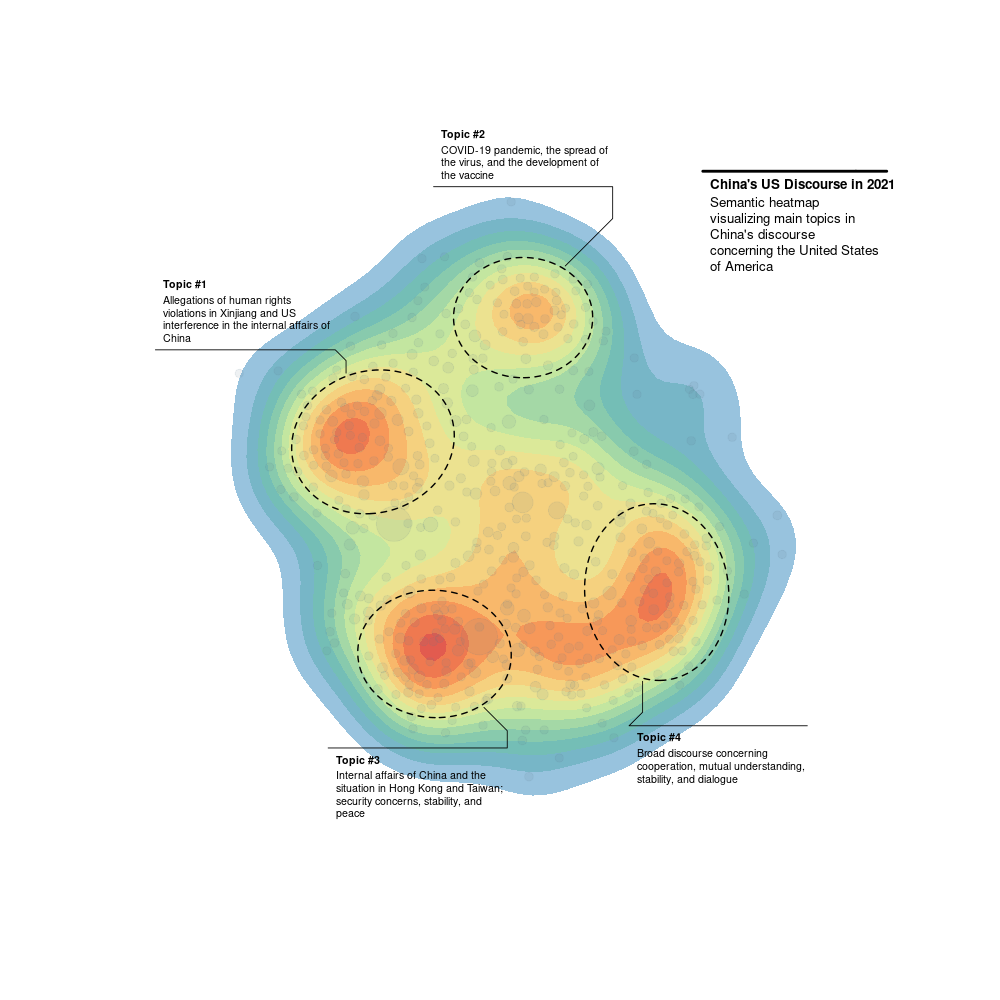
Semantic heatmap summarizing China’s discourse concerning the United States of America in 2021 (work in progress). Using the latest update of the Chinese Ministry of Foreign Affairs Press Conferences Corpus (CHMFA PressCon; v2 link) the graph presents general topics in China’s discourse when mentioning the US. It is based on a model which identifies statistically significant co-occurring words and connects them into a semantic network. The network is then analyzed for potential clusters of topics and visualized using a projection of their clustering magnitude into a two/three-dimensional space. 2D
3D
|
|
Graphs visualize semantic networks of COVID-19 discourse in three Southeast European countries – Bosnian-Herzegovina, Croatia, and Serbia. The networks are based on textual responses to a question concerning assigning blame for the pandemic collected from 5530 participants of a survey conducted between 27 April and 16 May 2020. The graphs summarize two subcorpora – responses written by those who believe in conspiracy theories (red graph for “believers”) and those who do not (blue graph for “non-believers”). The discourse models are based on pairwise correlations computed among words using phi coefficients. Word dyads with phi coefficient >=0.1 are visualized in the network layout capturing the prevailing discourse of the two groups. Both graphs show labels for words that are among the first 150 most frequent words in the respective sub-corpus. See more in Glaurdić, Josip, Christophe Lesschaeve, and Michal Mochtak (2022): Coronavirus Conspiracy Theories in Southeast Europe: (Non-)Believers, Social Network Bubbles, and the Discourse of Blame. Problems of Post-Communism, (online): 1-14. link
|
|
Mapping the war-related discourse in Croatian parliamentary debates. The graphs are part of a paper presented on workshop Postwar Politics: memory, Amnesia, and Denial in the Service of Electoral Victory organized on 20 – 21 February 2020 in Luxembourg City and later published by Government and Opposition. The first graph presents a 3D (interactive) visualization of semantic networks of war-related keywords used by veteran and non-veteran MPs in Croatian Sabor. The studied debates dealt with war-related issues concerning the system of benefits for Croatian war veterans and their family members. The underlying models are based on pairwise correlations computed among words (using phi coefficients) and track 55 most frequent war-related keywords used by Croatian MPs.
The second set of graphs visualizes the semantic networks of 100 most frequent uingrams used by veteran and non-veteran MPs mapping the overall prevailing discourse in both debates. War-related keywords are highlighted in grey.
|
|
Interactive version of Figure 6 in Looking Eastward: Network Analysis of Czech Deputies and their Foreign Policy Groups co-authored by Tomas Diviak; Problems of Post-Communism (2019; online). |
|
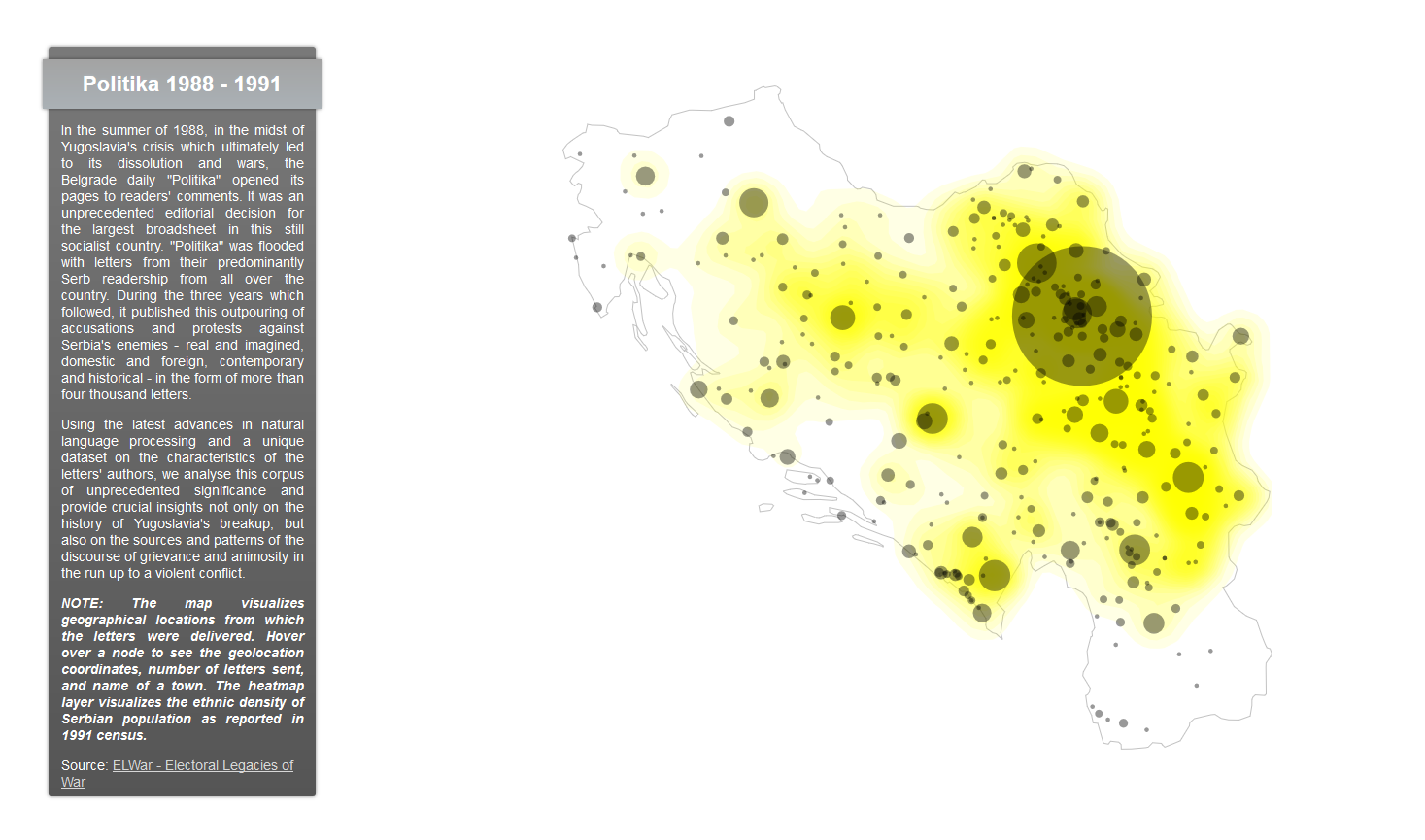
Interactive map visualizing geographical locations from which letters published by Yugoslav newspaper Politika were sent. The heatmap layer visualizes the ethnic density of Serbian population as reported in 1991 census. Data were extracted from Politka corpus as a part of ongoing research project focused on political discourse in former Yugoslavia before the outbreak of Yugoslav wars (1988 – 1991).
|
|
3D rendering of an interactive graph presented as a part of Impresso Talk on June 5, 2019 at the University of Luxembourg. Graph visualizes relations of topics extracted from Politka corpus (see legend for more info), an ongoing research project focused on political discourse in former Yugoslavia before the outbreak of Yugoslav Wars (1988 – 1991). For exploring the graph, “grab” the part you are interested in and move it.
|